We are creative, ambitious and ready for challenges!
aiPages



Block identification
aiPages is able to identify the following content blocks in any newspaper pages:
- Articles
- Titles in articles
- Authors of articles
- Images in articles
- Columns in articles
- Advertisements
Text Classification
- aiPages is classifying text according to its content e.g. art, sports, politics,...
- aiPages uses topic classification derived from (IPTC).
- aiPages is able to identify 72 different categories in Arabic. This is critical for serious data analysis and indexing.
Metadata Extraction
- Title of article
- Author of article
- Images in the content block
- Named entities, each extracted named entity will be linked to a publicly published database and could by a place, person or an organization.
Text Extraction
- Text extraction is conducted whether the text falls into one or more columns.
- It can recognize poorly scanned images using pre-processing of image as final NLP processing of extracted content to correct any OCR misidentified letters or words.
Text Summarization
- aiPages is able to identify the most interesting parts of extracted text and stitch them into a meaningful summary.
- In very long articles, the summary could be only 20-30% of the extracted article.
User access management
- aiPages management involves creating and managing user accounts, defining access levels, and enforcing security policies to ensure that users only have access to the parts of the system and data that they need to perform their jobs.
Dashboard
- The Dashboard Monitor is a robust visualization tool aimed at providing users with comprehensive insights into the processing status of Documents, Pages, and Articles. With an interactive interface, users can filter results by date, choose between different content type views, and get real-time updates, all in one unified dashboard.
Search Capabilities
- aiPages employs a cutting-edge search engine harnessing Semantic Search capabilities. This search type prioritizes understanding the context and meaning of queries over mere keyword matching. By utilizing natural language processing (NLP) and machine learning, it analyzes both the query and the document content, delivering highly relevant and accurate results.
Operational Efficiency
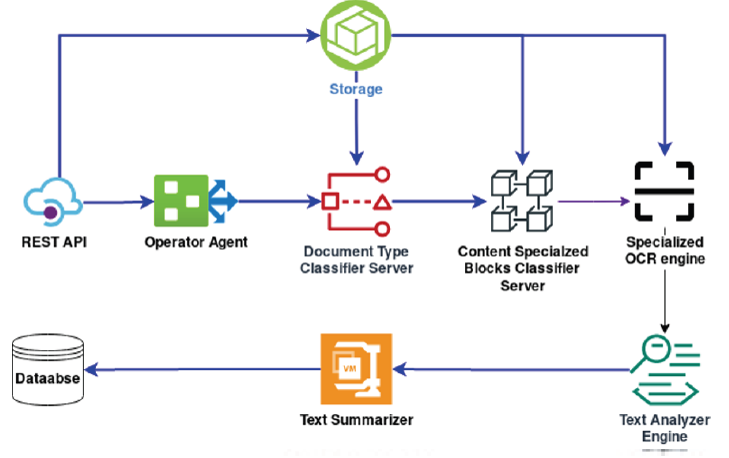
- Since the solution is composed of various micro services and components, it might happen that some components are under heavy utilization compared to the others, this is totally managed by operator agent that scales up/down components according to its load without need to scale the other components for maximum operational efficiency.

Image segmentation

Named Entity Recognition (NER)
- This is the technology of allowing the computer to understand different parts of an image.
- Image segmentation is the core of our system's ability to differentiate content blocks from other not interesting blocks like advertisements, images and classified ads.
- It can identify content blocks even if they are not in a regular geometric shape (e.g. squares or rectangles) which is very common in modern papers.

OCR
- Convolutional neural networks: It is particularly effective for image recognition tasks. They work by processing small regions of an image and using learned features to classify the content.
- Long short-term memory (LSTM) networksIt is a type of neural network that is effective for processing sequential data and improve the recognition accuracy. They work by maintaining a memory of previous inputs to inform future predictions.
- Hidden Markov Models (HMMs): Tesseract uses HMMs to model the probability distribution of characters within an image.